Brain Dissection: fMRI-trained Networks Reveal Spatial Selectivity in the Processing of Natural Images
Gabriel Sarch Michael Tarr Katerina Fragkiadaki* Leila Wehbe*
Carnegie Mellon University
 Paper
Paper
 Code
Code
 Interactive
Interactive
 Citation
Citation
Abstract
The alignment between deep neural network (DNN) features and cortical responses currently provides the most accurate quantitative explanation for higher visual areas. At the same time, these model features have been critiqued as uninterpretable explanations, trading one black box (the human brain) for another (a neural network). In this paper, we train networks to directly predict, from scratch, brain responses to images from a large-scale dataset of natural scenes. We then employ "network dissection" (Bau et al., 2017), a method used for enhancing neural network interpretability by identifying and localizing the most significant features in images for individual units of a trained network, and which has been used to study category selectivity in the human brain (Khosla & Wehbe, 2022). We adapt this approach to create a hypothesis-neutral model that is then used to explore the tuning properties of specific visual regions beyond category selectivity, which we call "brain dissection".
We use brain dissection to examine a range of ecologically important, intermediate properties, including depth, surface normals, curvature, and object relations across sub-regions of the parietal, lateral, and ventral visual streams, and scene-selective regions. Our findings reveal distinct preferences in brain regions for interpreting visual scenes, with ventro-lateral areas favoring closer and curvier features, medial and parietal areas opting for more varied and flatter 3D elements, and the parietal region uniquely preferring spatial relations. Scene-selective regions exhibit varied preferences, as the retrosplenial complex prefers distant and outdoor features, while the occipital and parahippocampal place areas favor proximity, verticality, and in the case of the OPA, indoor elements. Such findings show the potential of using explainable AI to uncover spatial feature selectivity across the visual cortex, contributing to a deeper, more fine-grained understanding of the functional characteristics of human visual cortex when viewing natural scenes.
How does brain dissection work?
Inspired by Khosla & Wehbe 2022, brain dissection provides a hypothesis-neutral approach for identifying the most significant image features for predicting the response of a specific voxel.
The method trains a convolutional neural network tailored to predict voxel responses to natural images within a defined sub-region. By training a backbone network for this sub-region and incorporating a linear readout for each voxel, the network learns to extract image features crucial for predicting each voxel (Figure A below). For training, we used the Natural Scenes Dataset (NSD), which consists of high-resolution fMRI responses to naturalistic images from Microsoft COCO.
After training, we "dissect" the network by inputting held-out images and extracting regions that the network considers most relevant for each voxel (Figure B below). Subsequently, we analyze properties of the voxel-selective regions within the images.
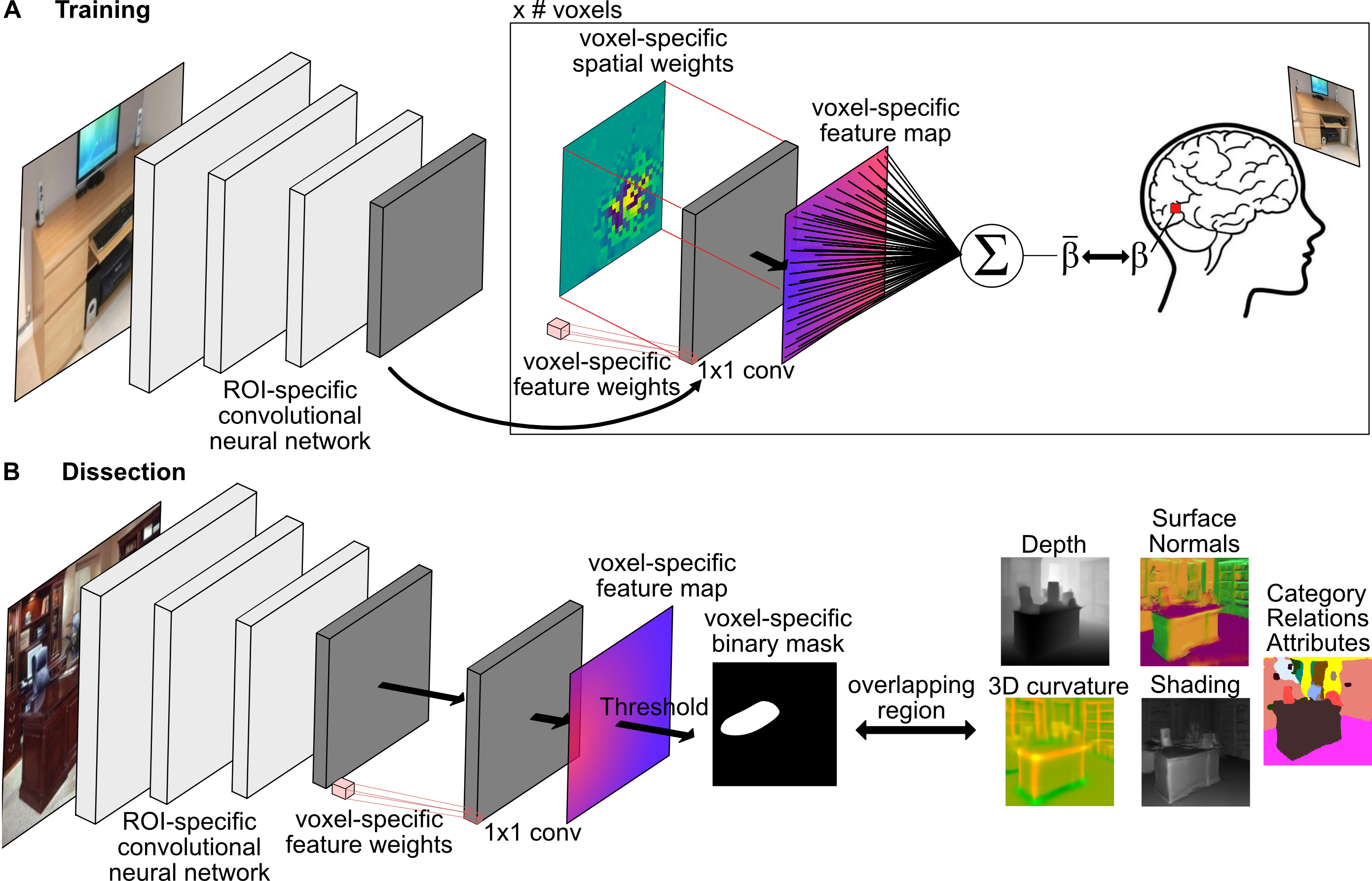
Results
Interactive Brain Flatmaps
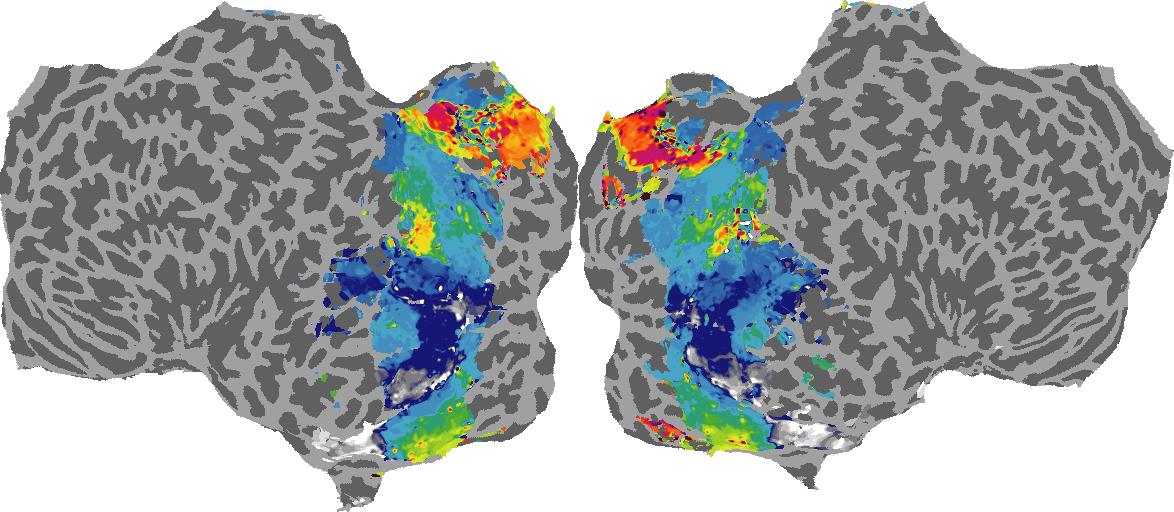
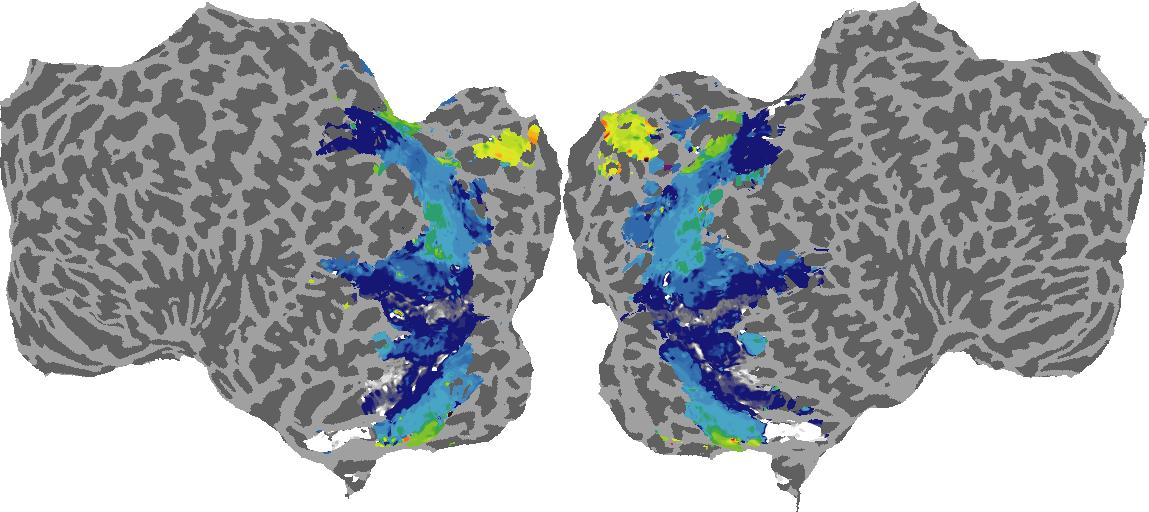
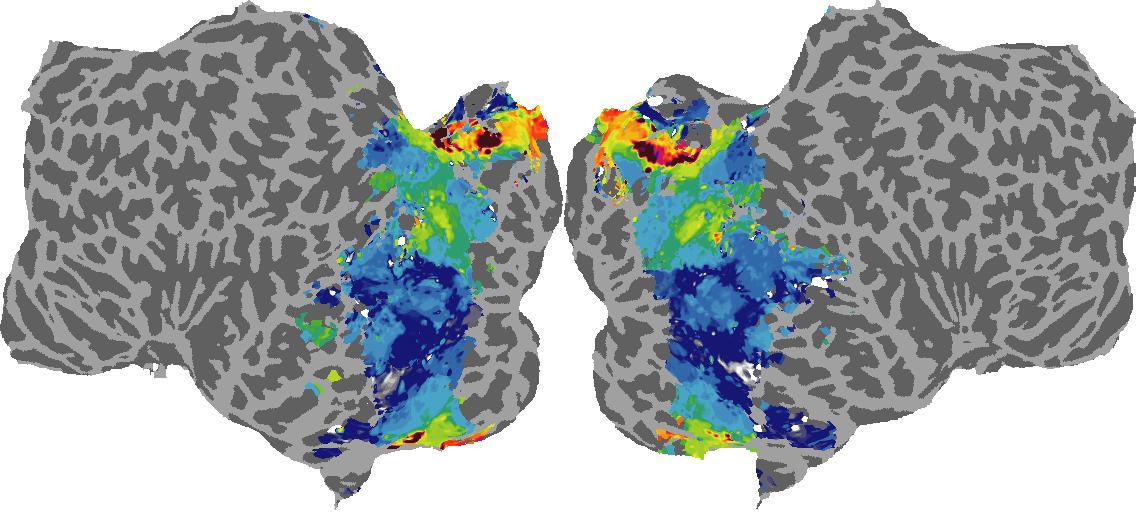
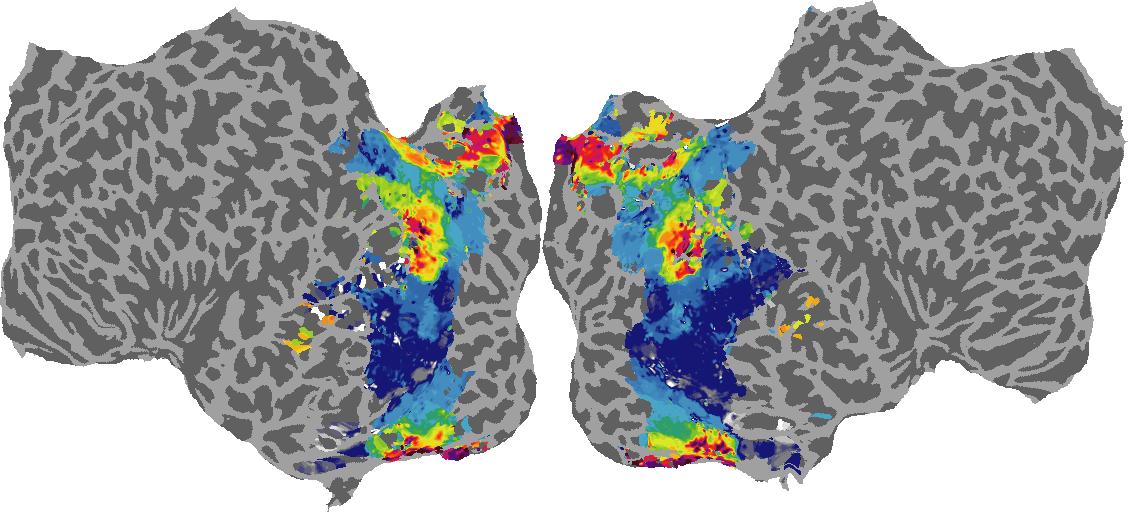
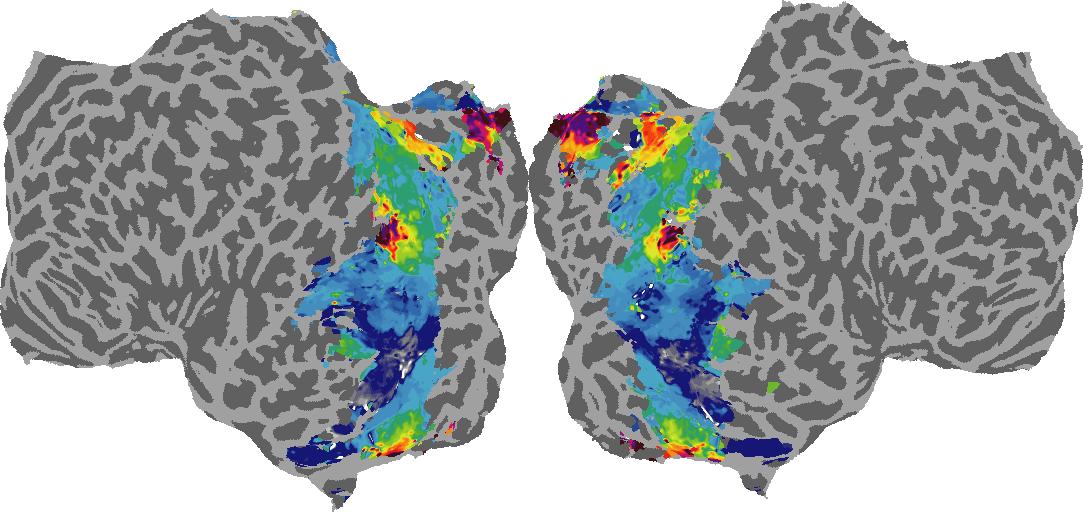
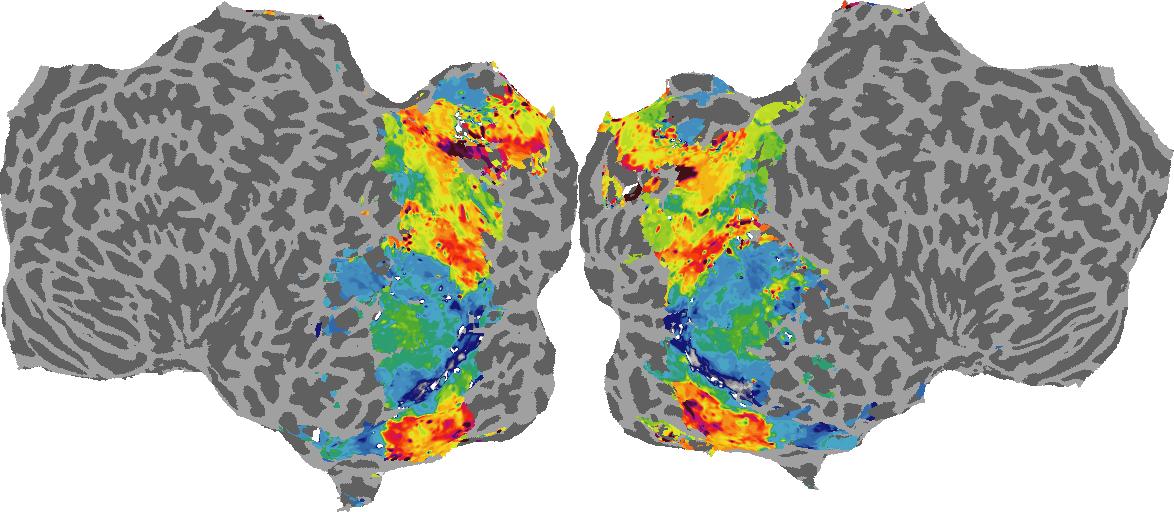
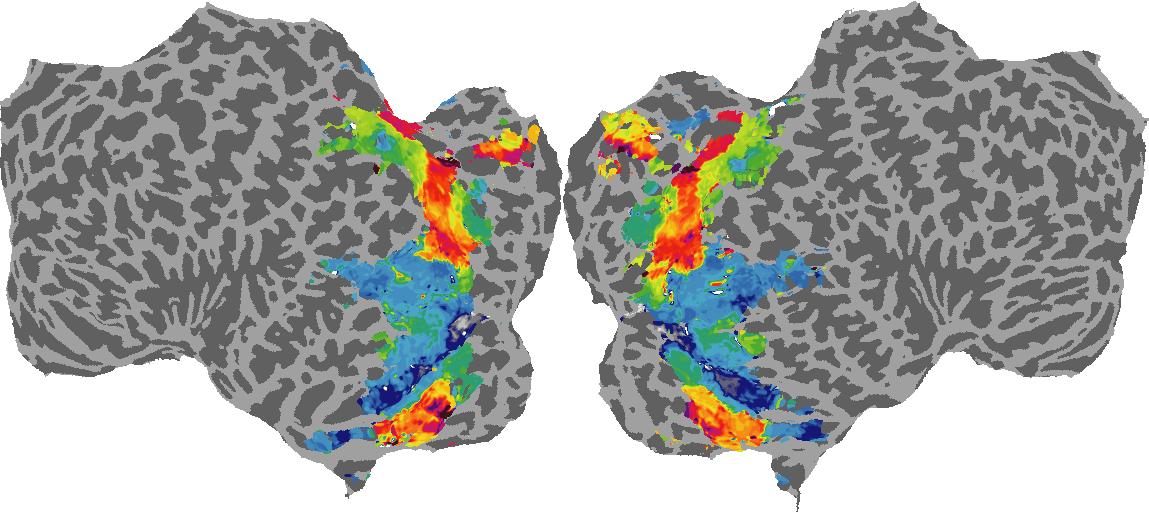
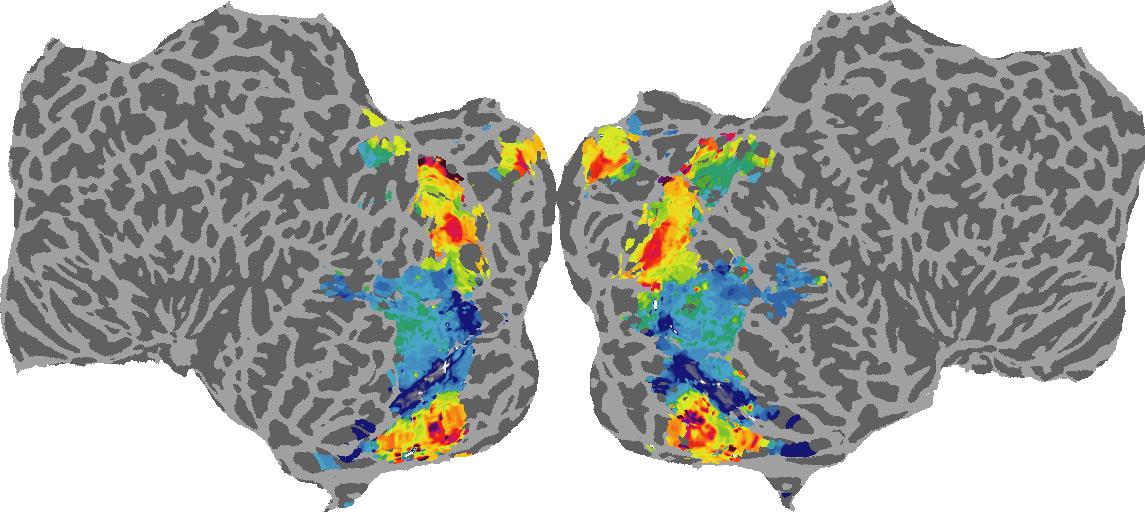
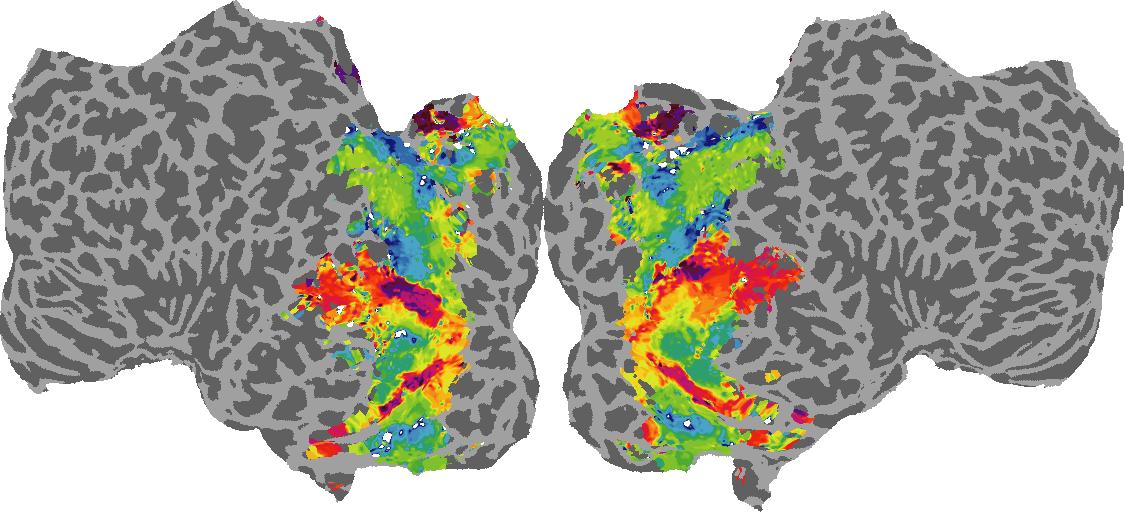
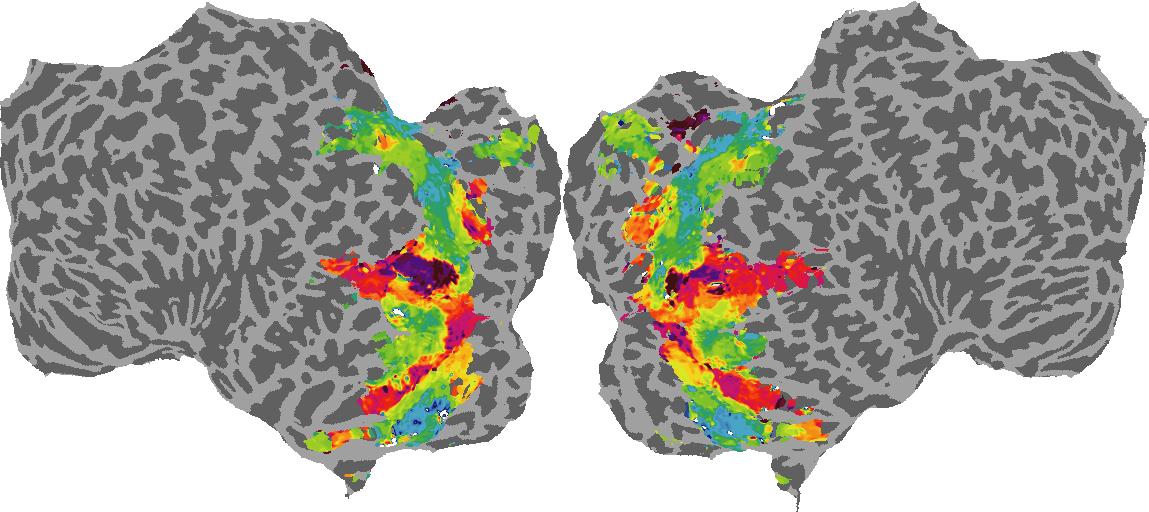
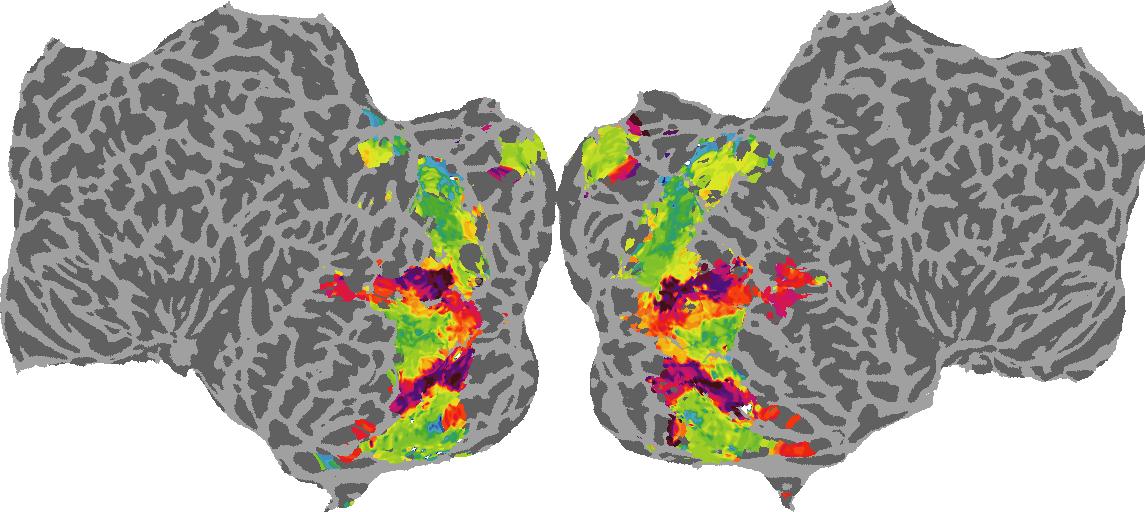
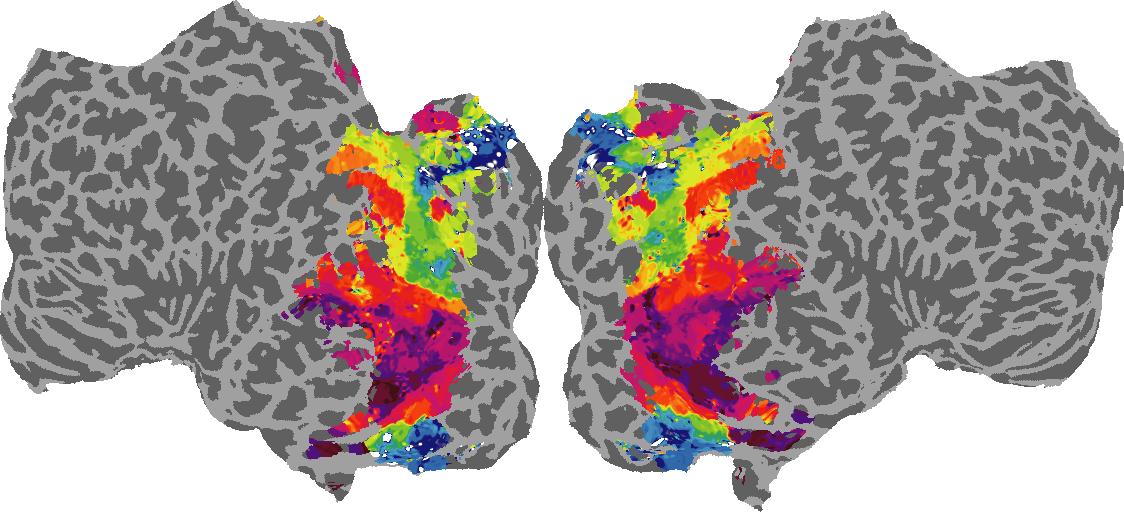
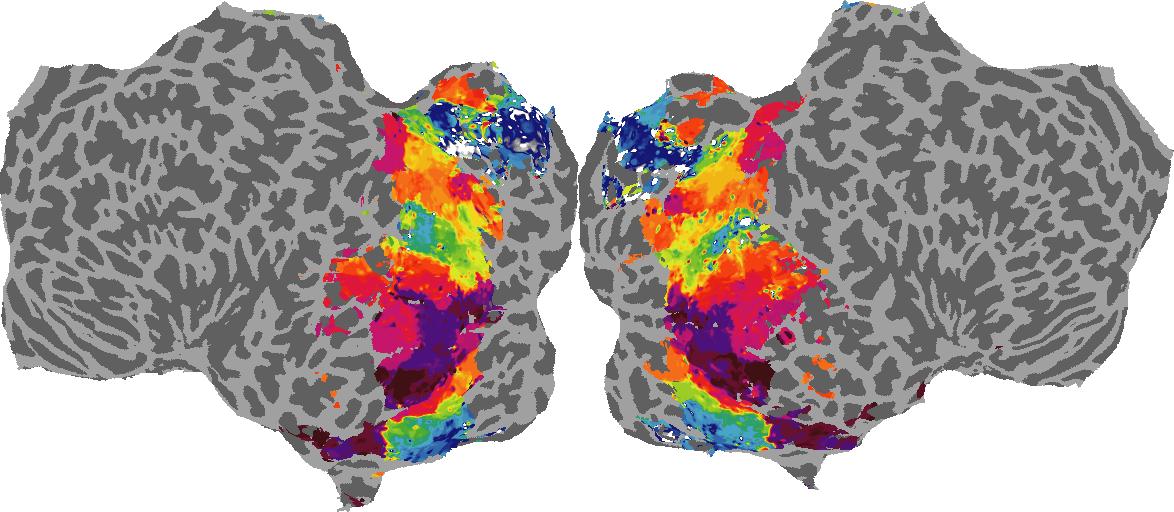
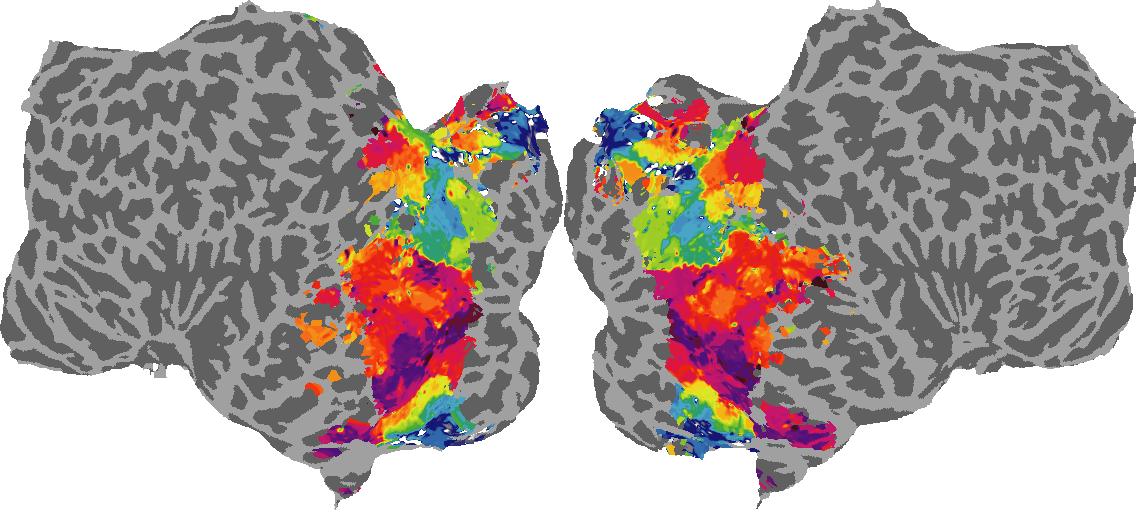
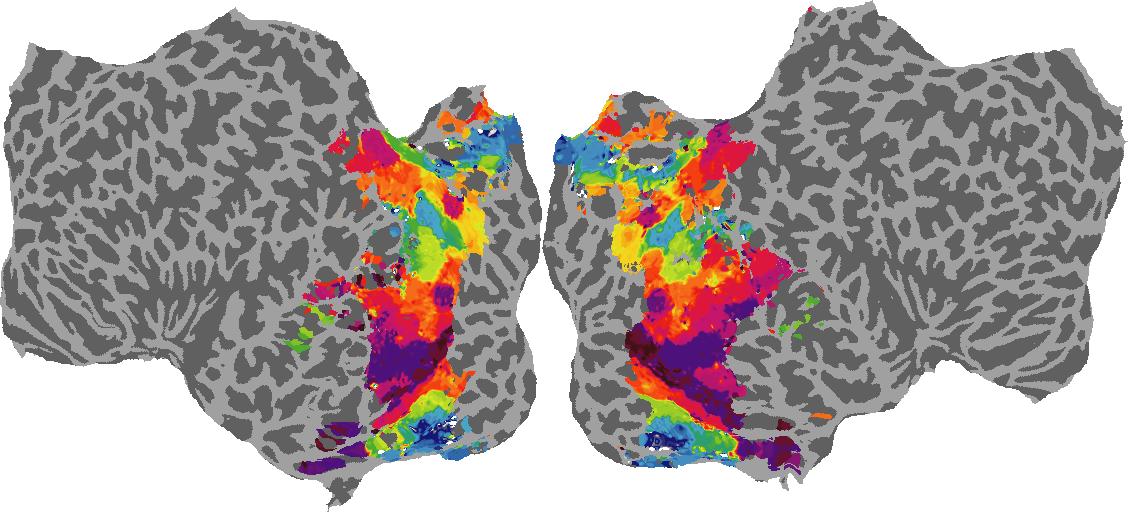
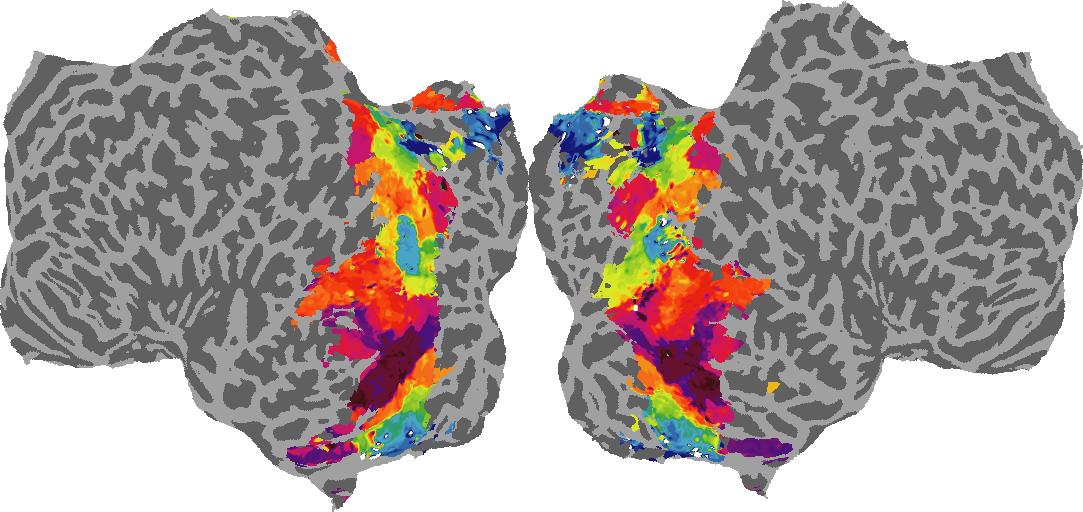
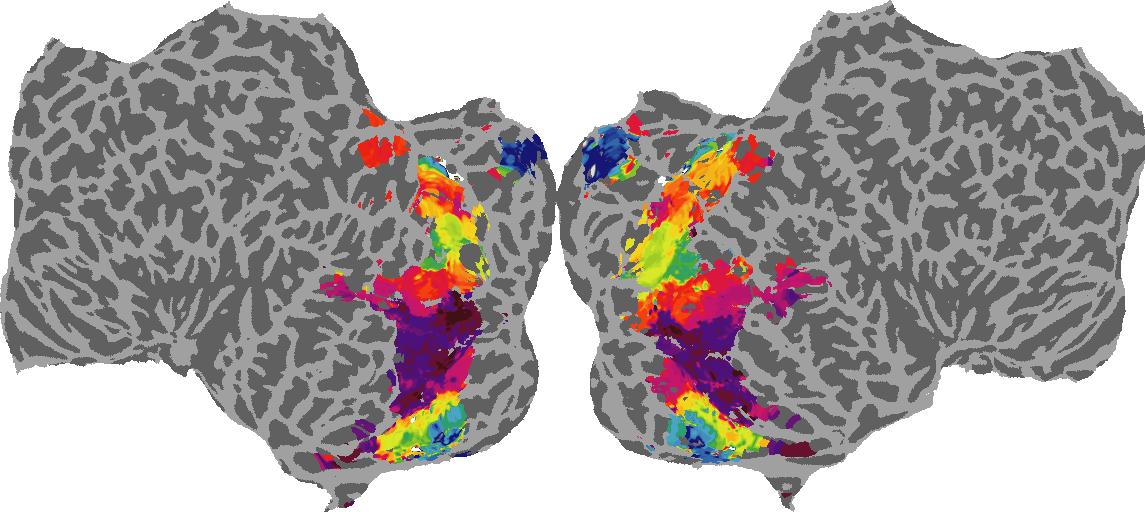
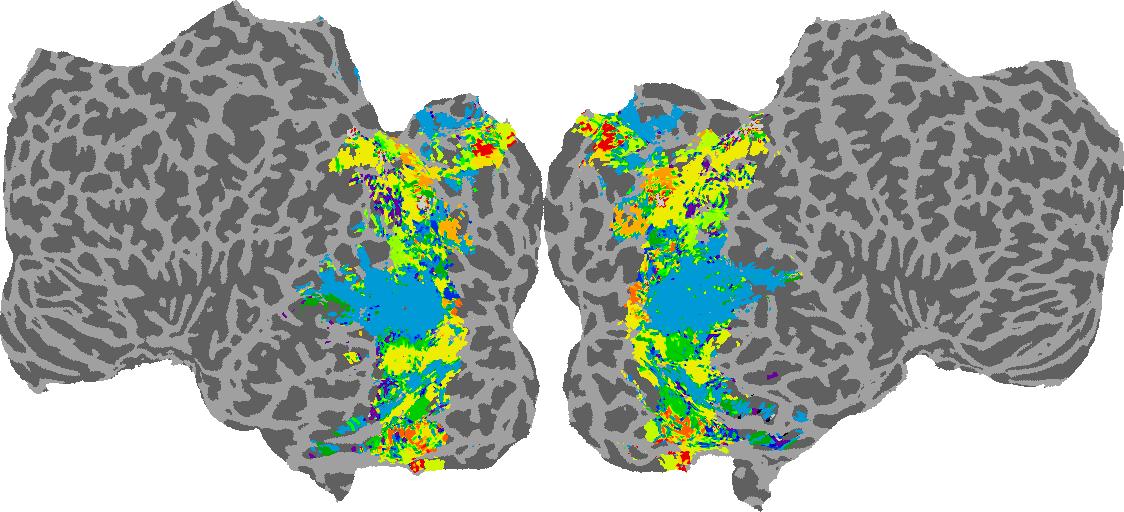
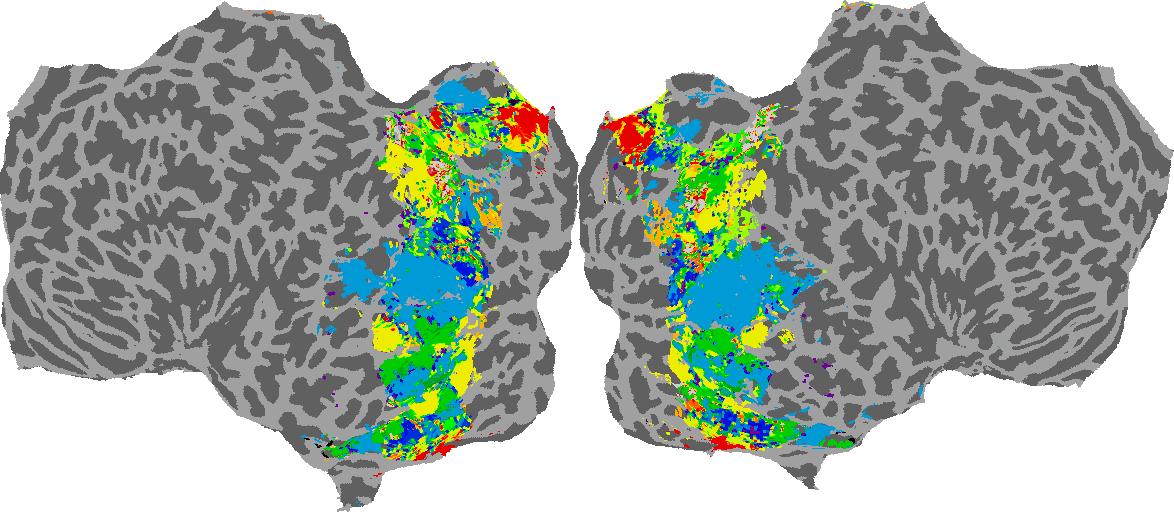
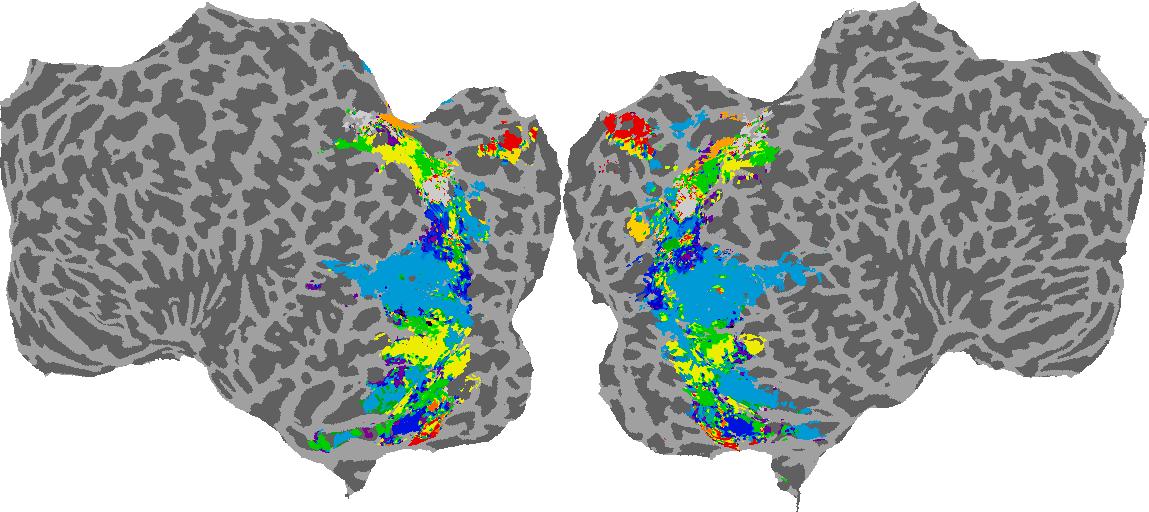
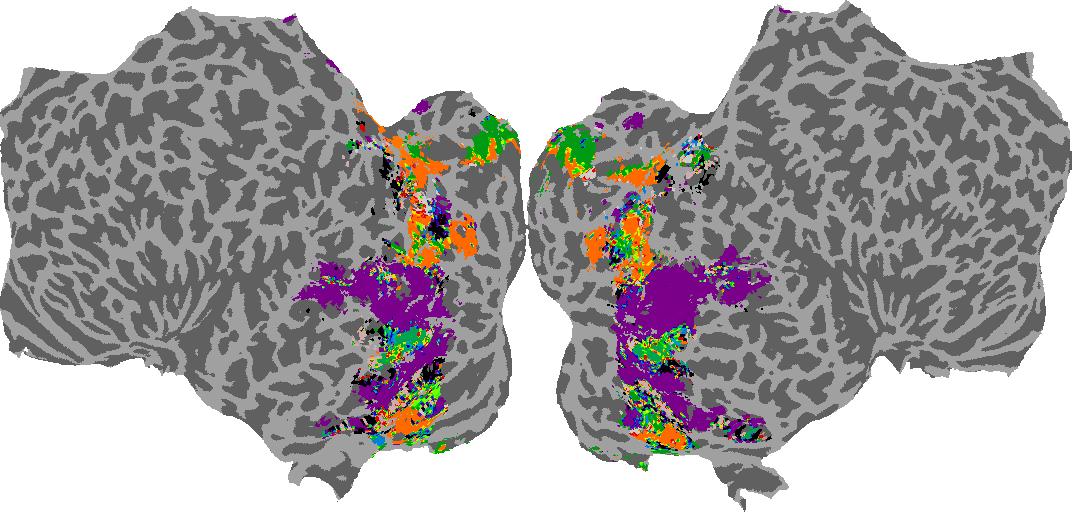
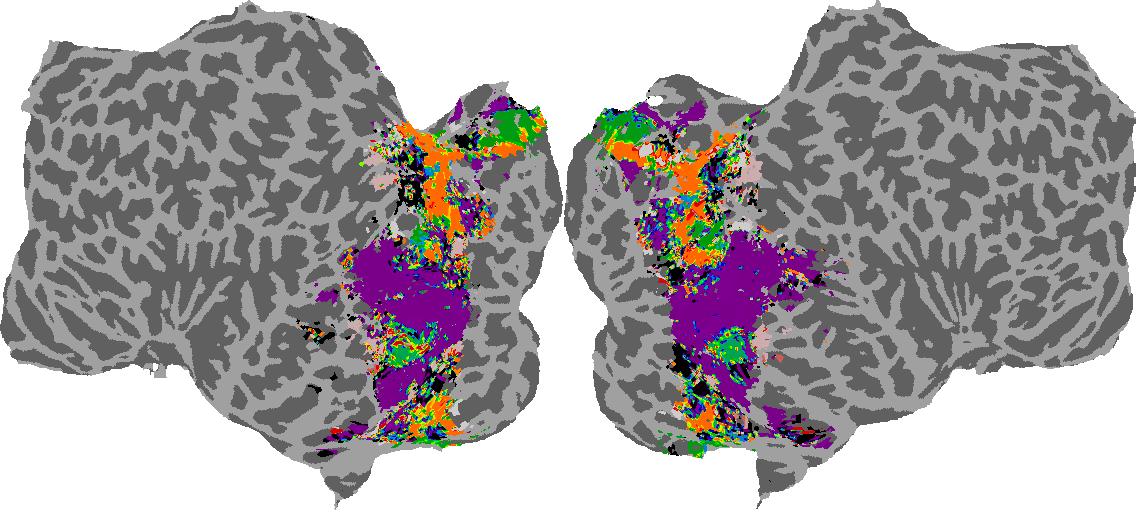
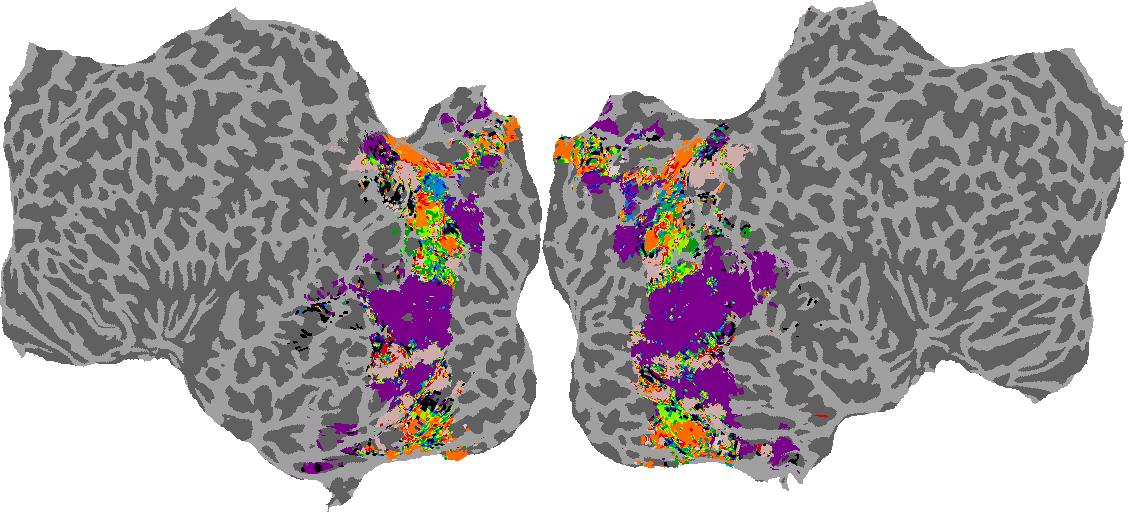
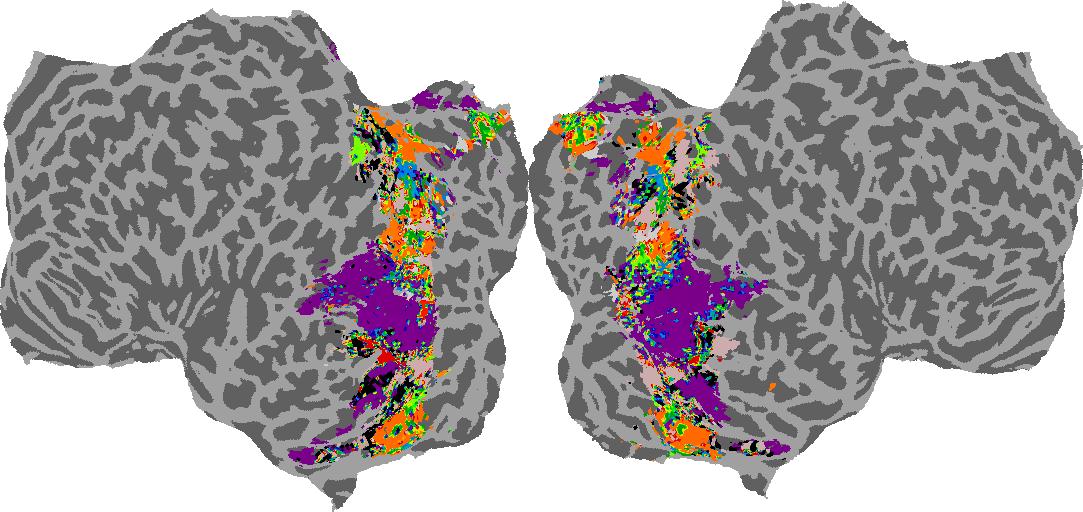
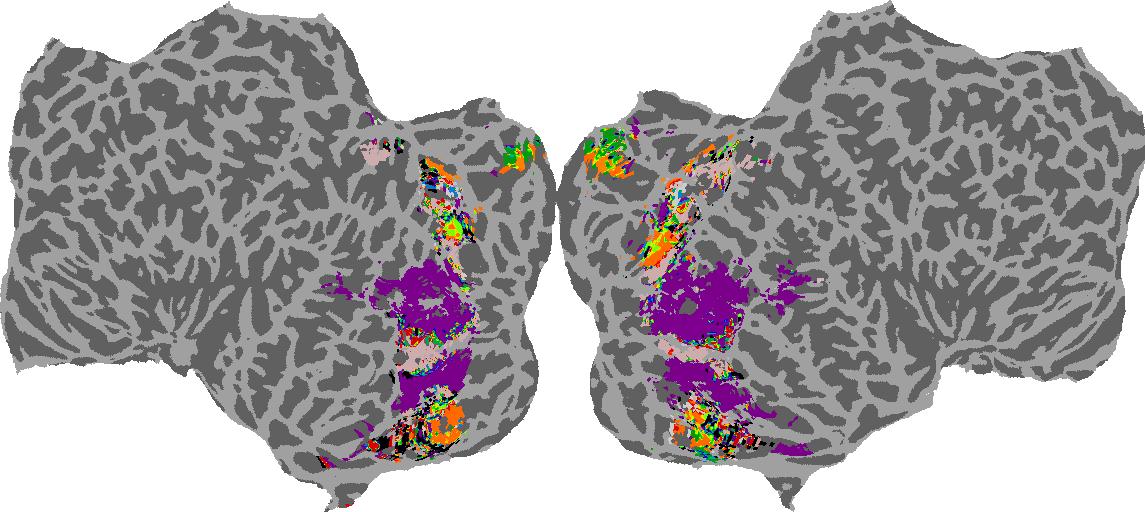
To gain a better understanding of how 3D structure is represented in the brain, we used brain dissection to quantify the selectivity (preference) for each voxel across the high-level visual cortex for the four spatial measures and two category datasets. This process allowed us to create a detailed selectivity (preference) map for each voxel that reveals how 2D inputs are transformed into 3D representations that enable reasoning about the physical world. Hover over the brain flatmaps below to reveal the selectivity value at that location. We rendered the voxel data on flatmap images using pycortex.
Instructions
To observe the voxel selectivity (preference) at a location on the flatmap:
1. Click on a subject
2. Hover over a location-of-interest on the brain map
Depth
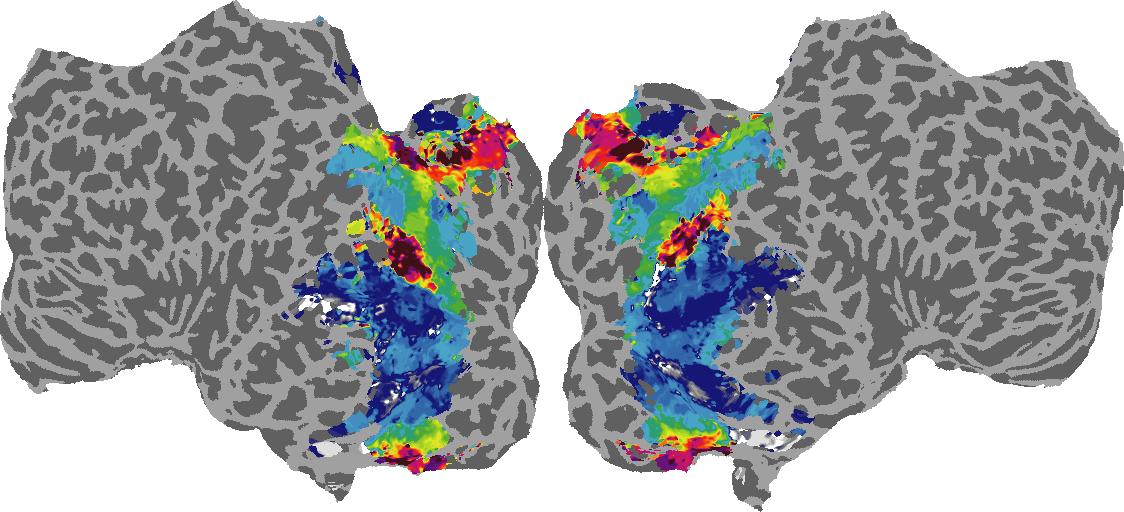
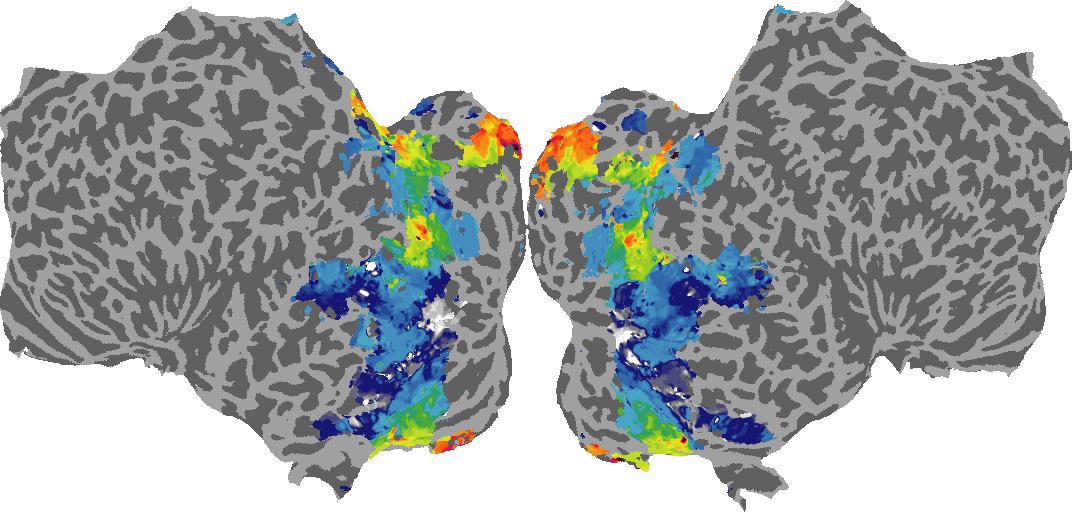
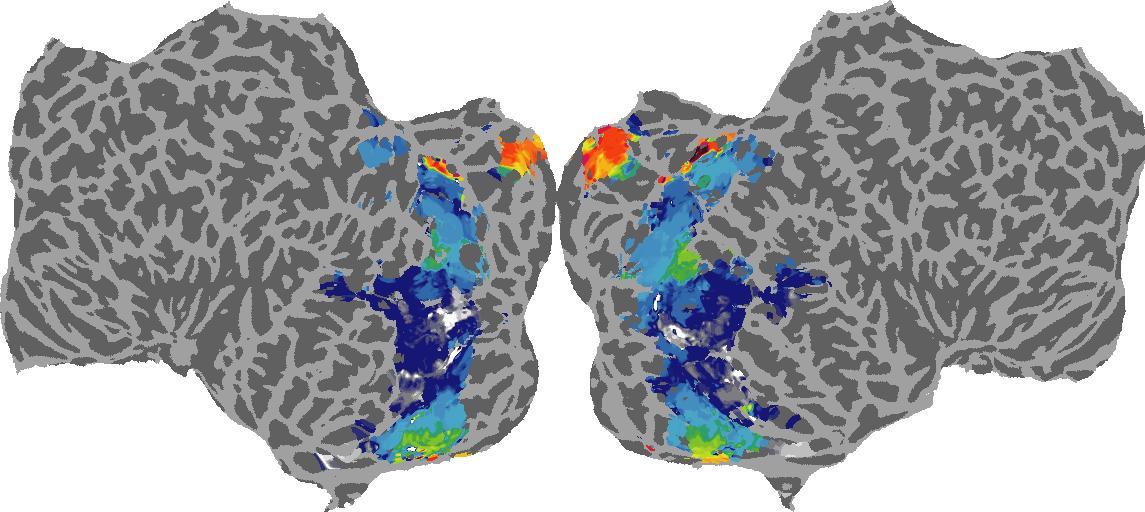
Depth: N/A meters
Surface Normals
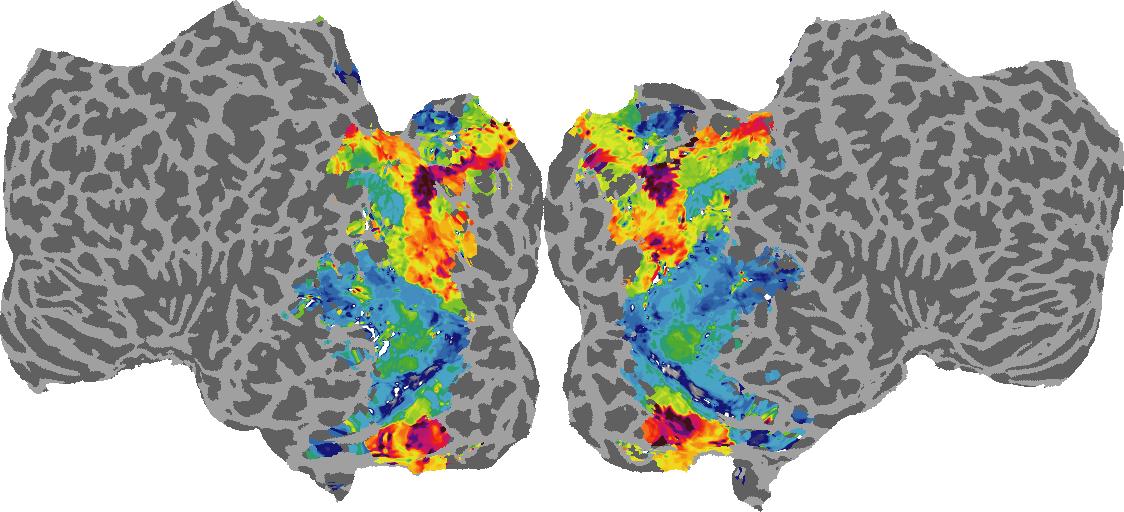
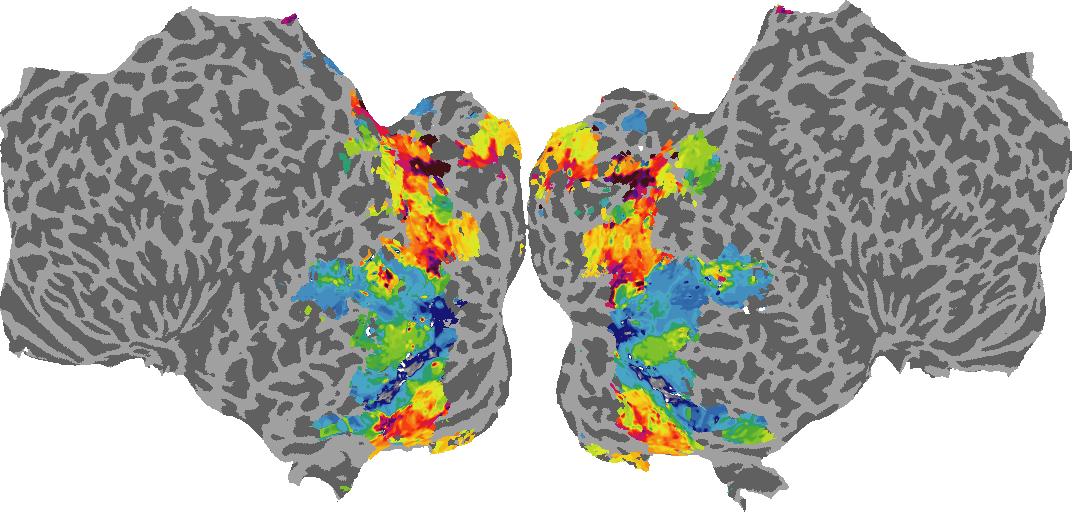
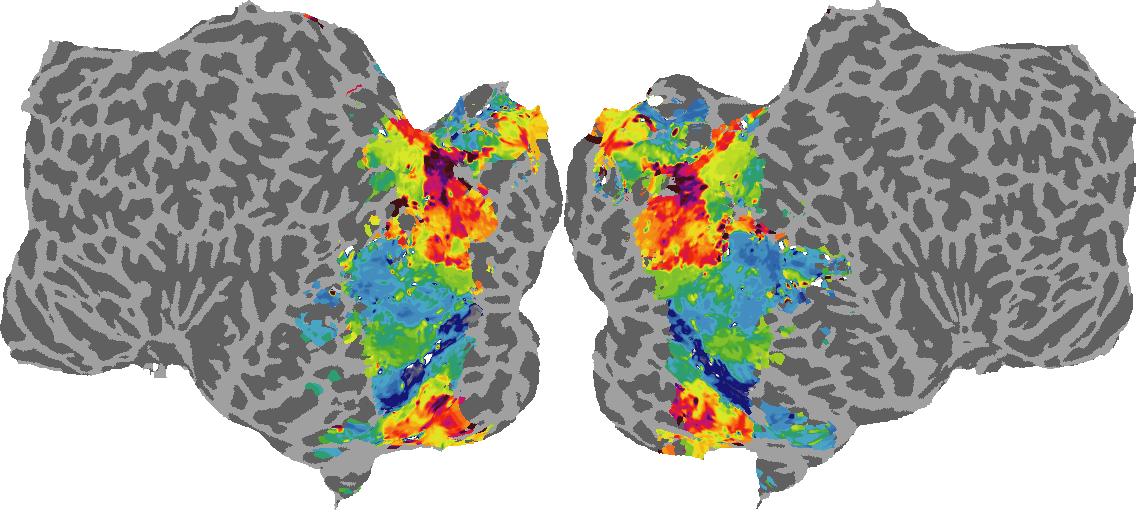
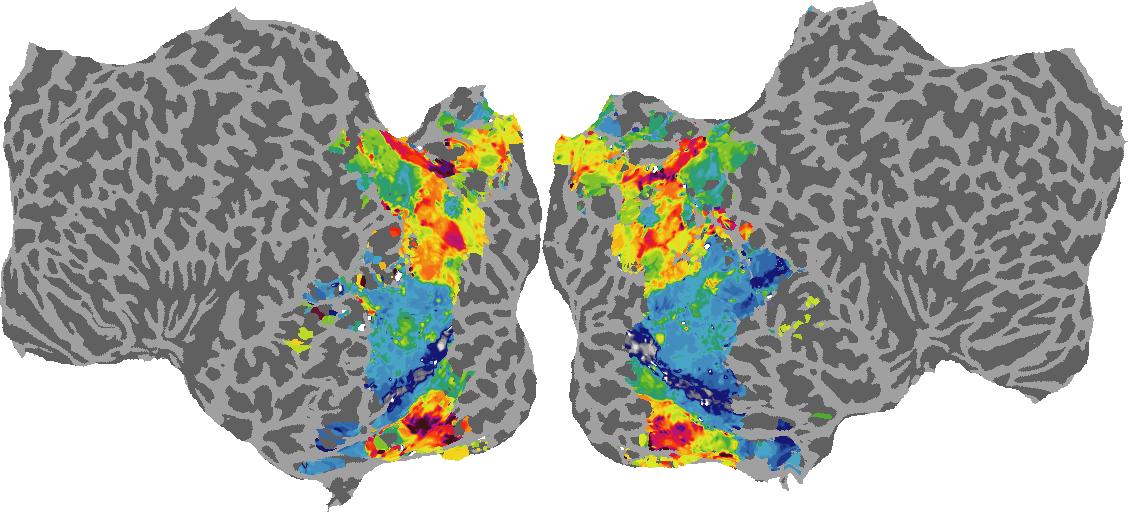
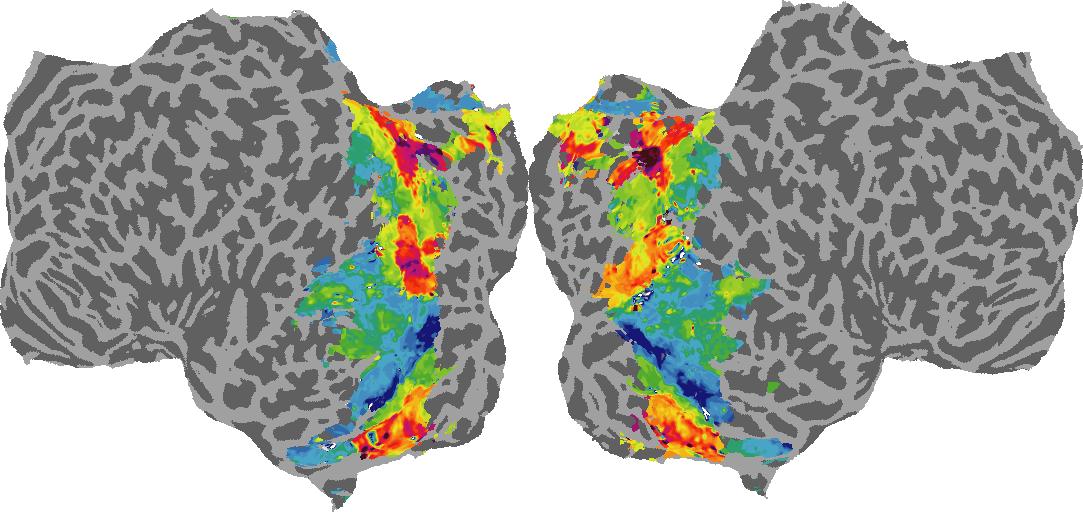
Surface Normal (bin): N/A
Guassian Curvature
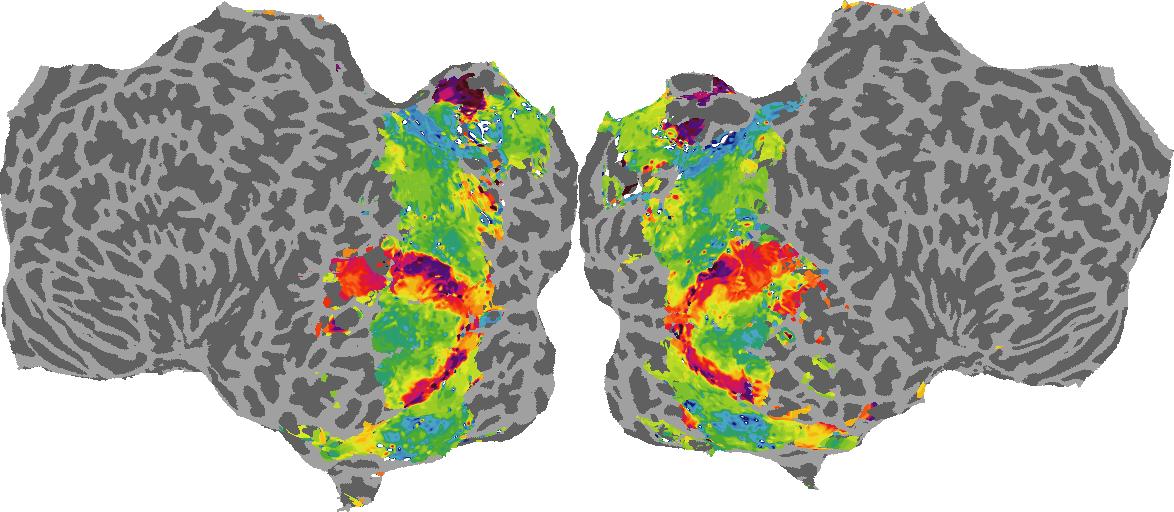
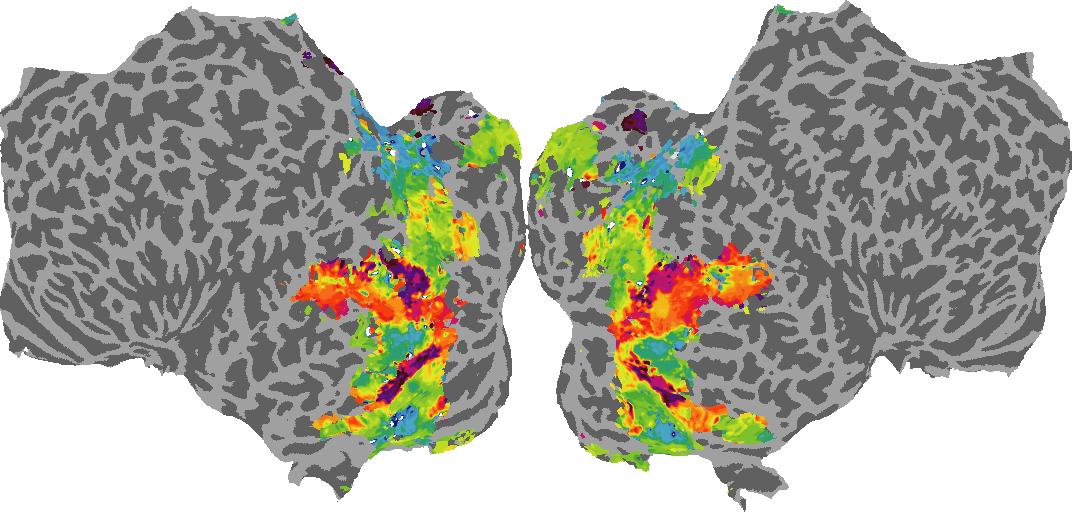
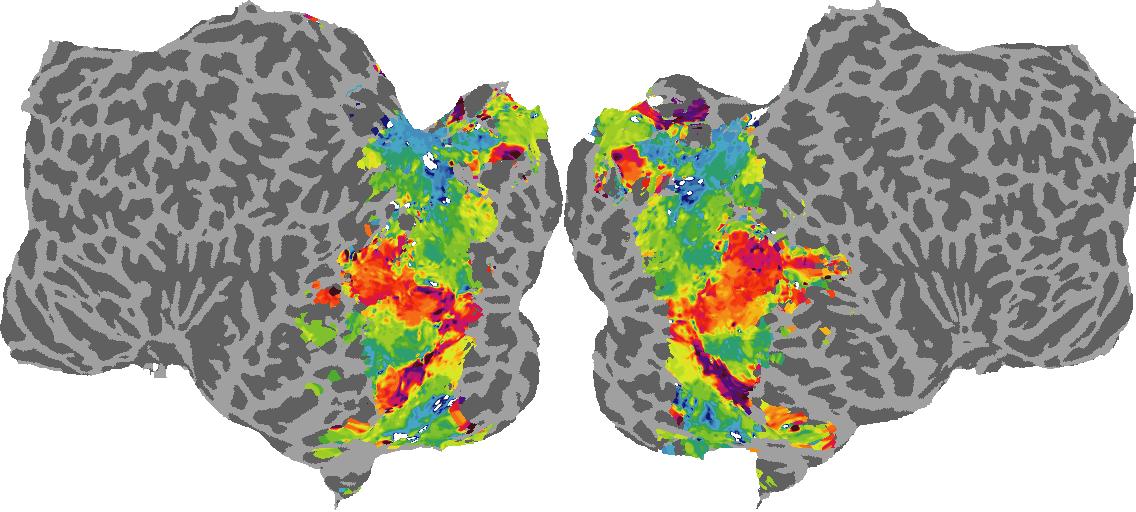
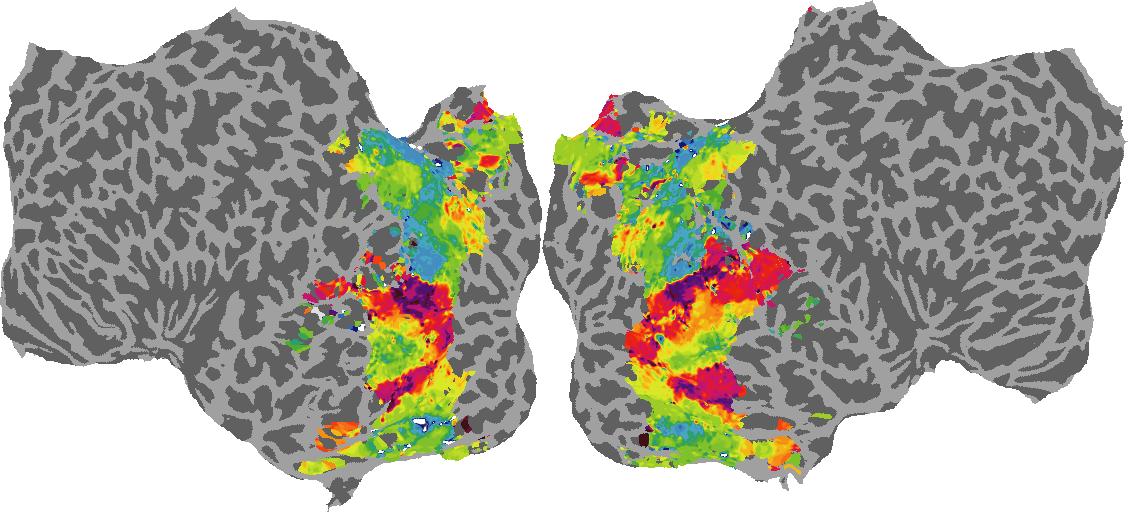
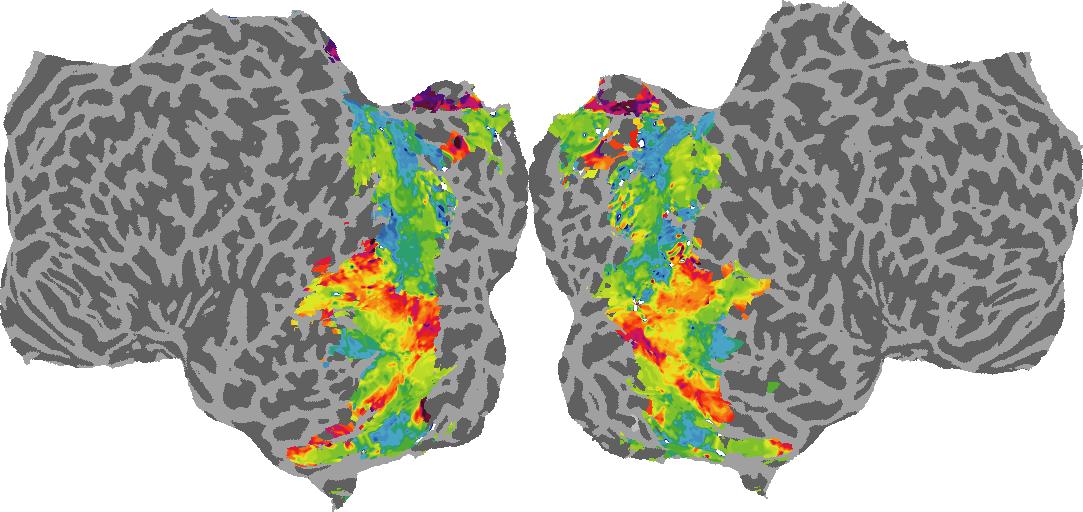
Guassian Curvature: N/A
Shading
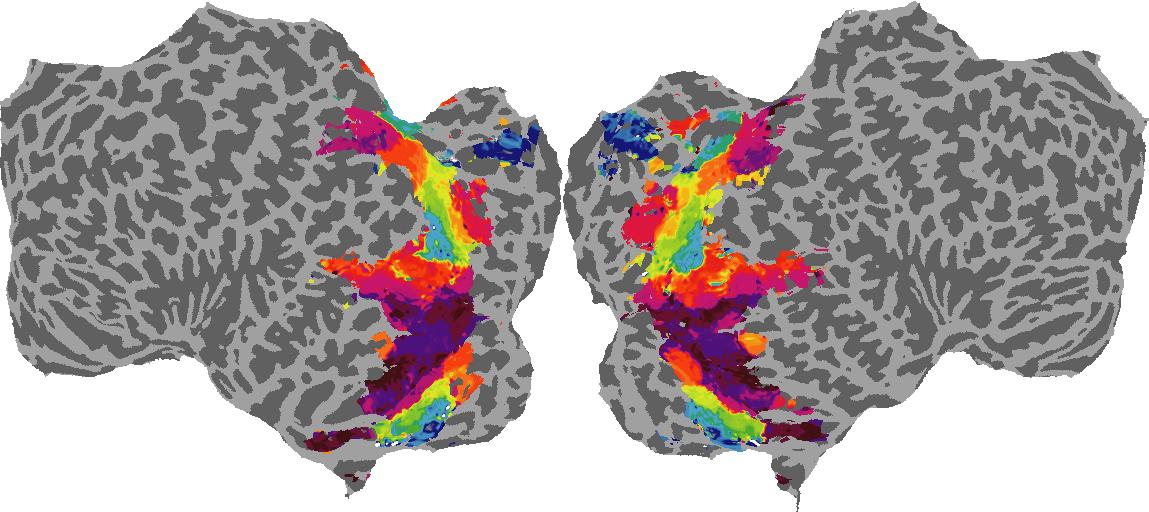
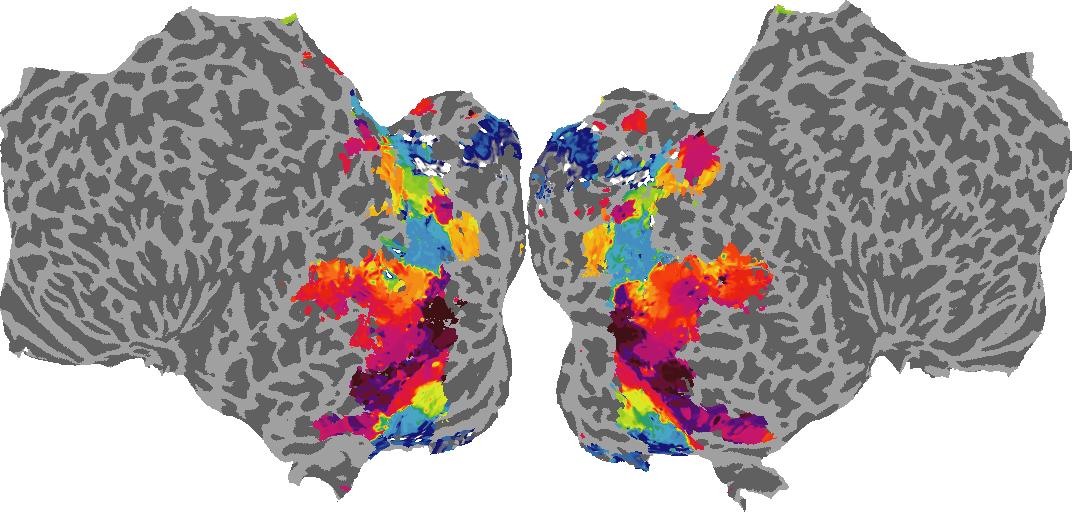
Shading: N/A
GQA / Visual Genome Category
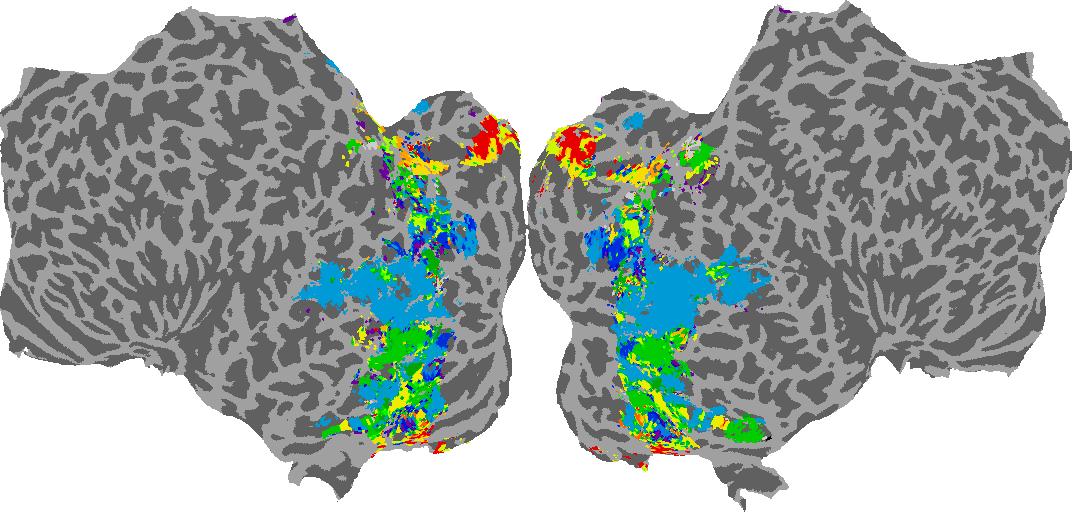
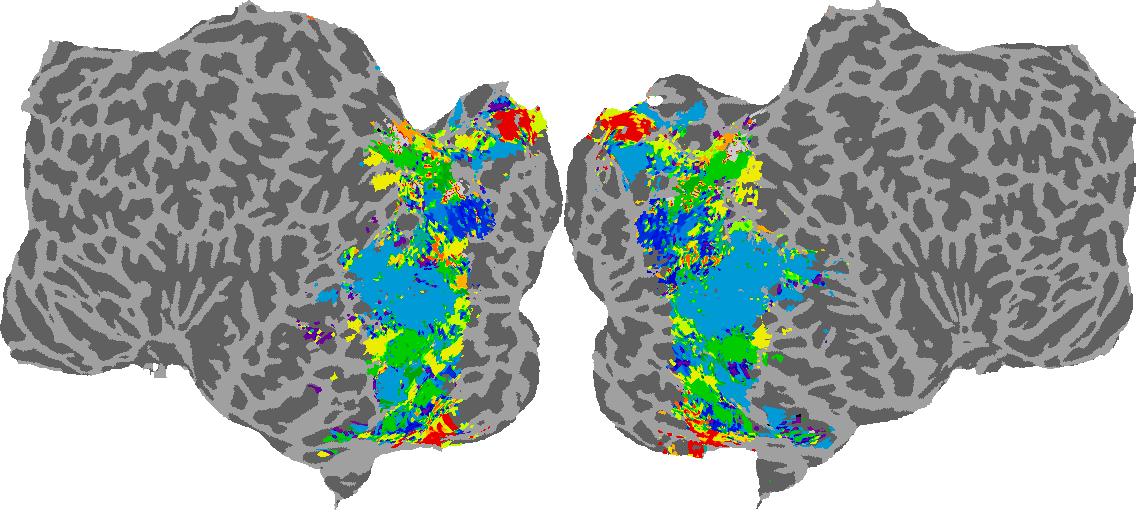
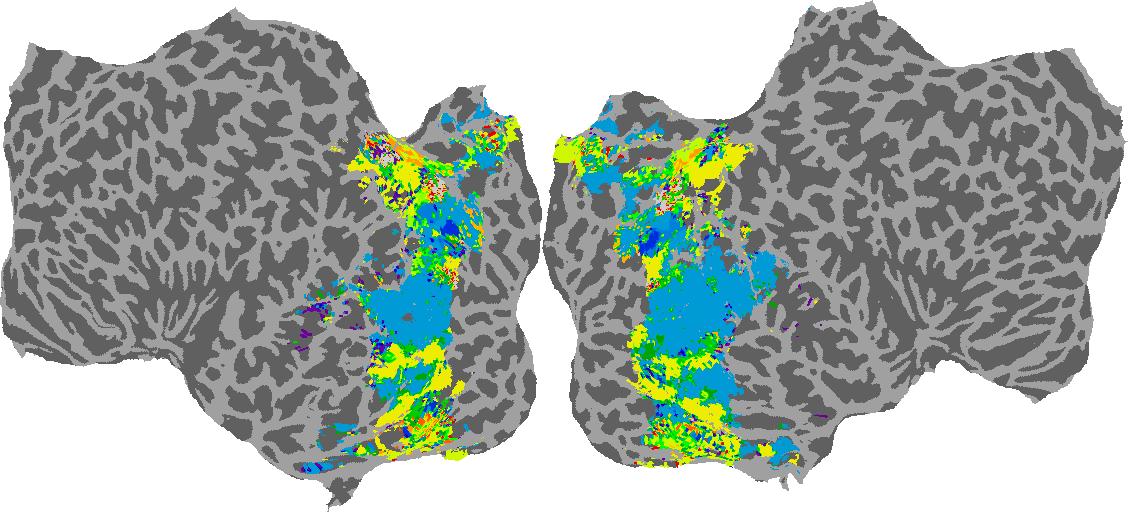
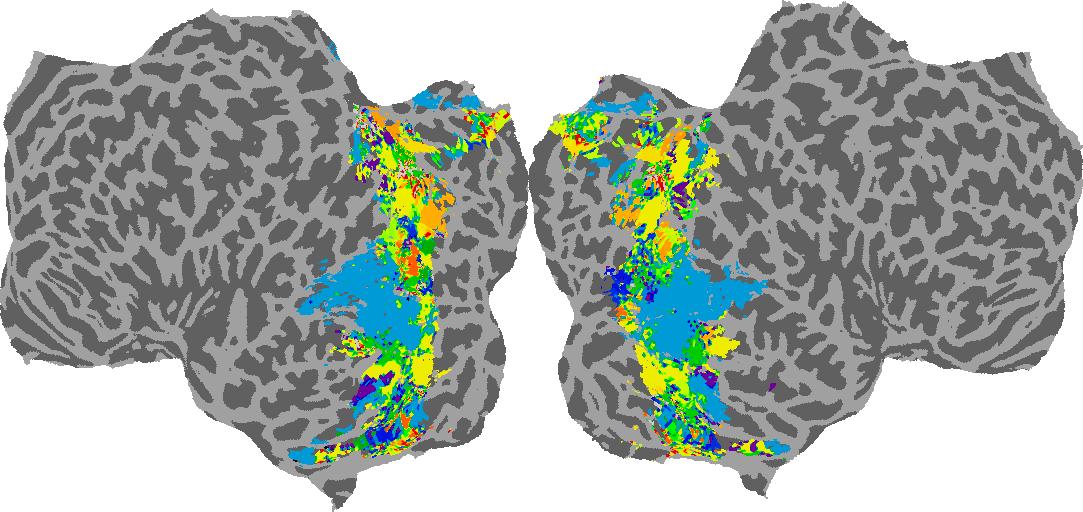
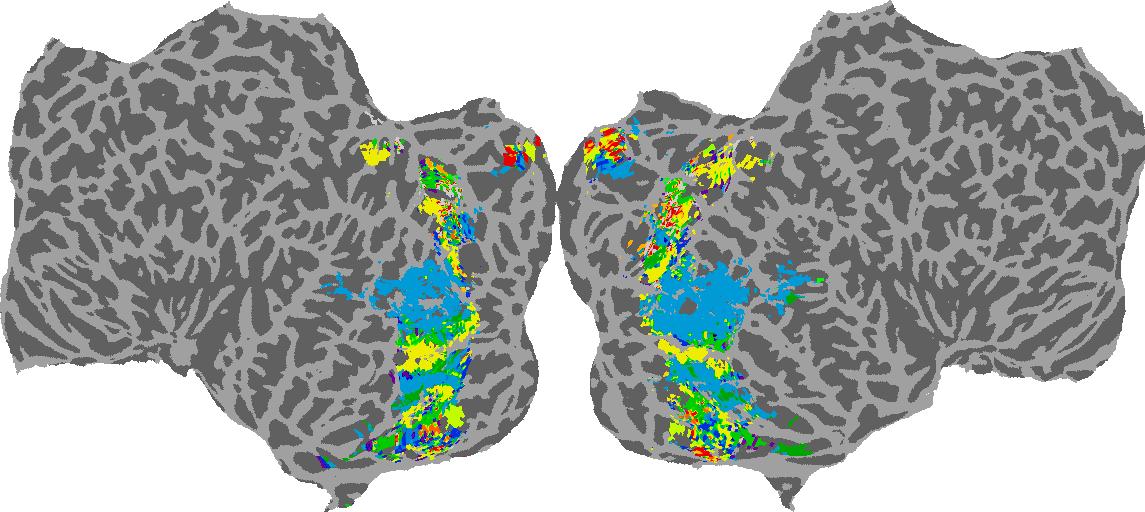
Category: N/A
Places365 Category
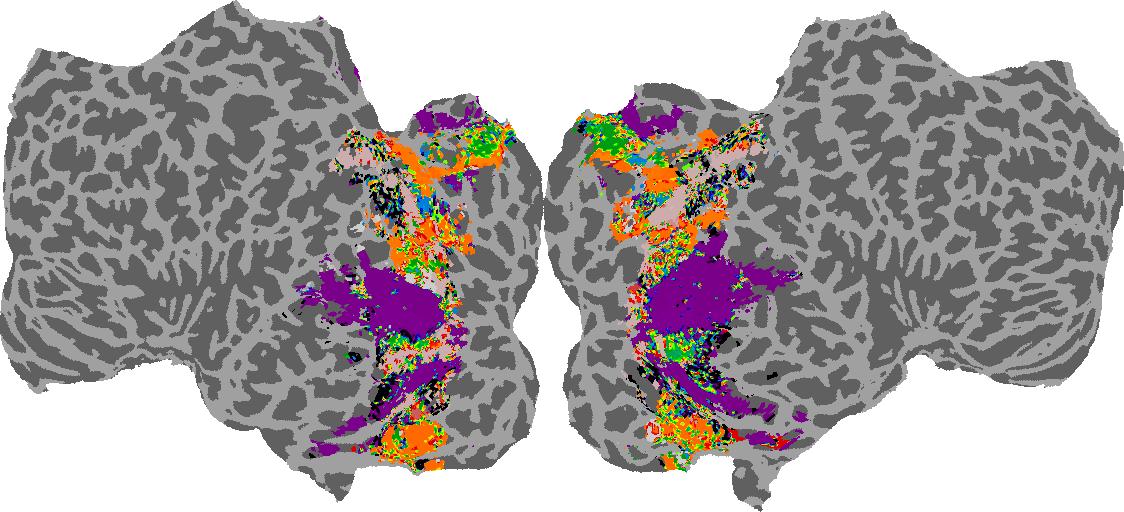
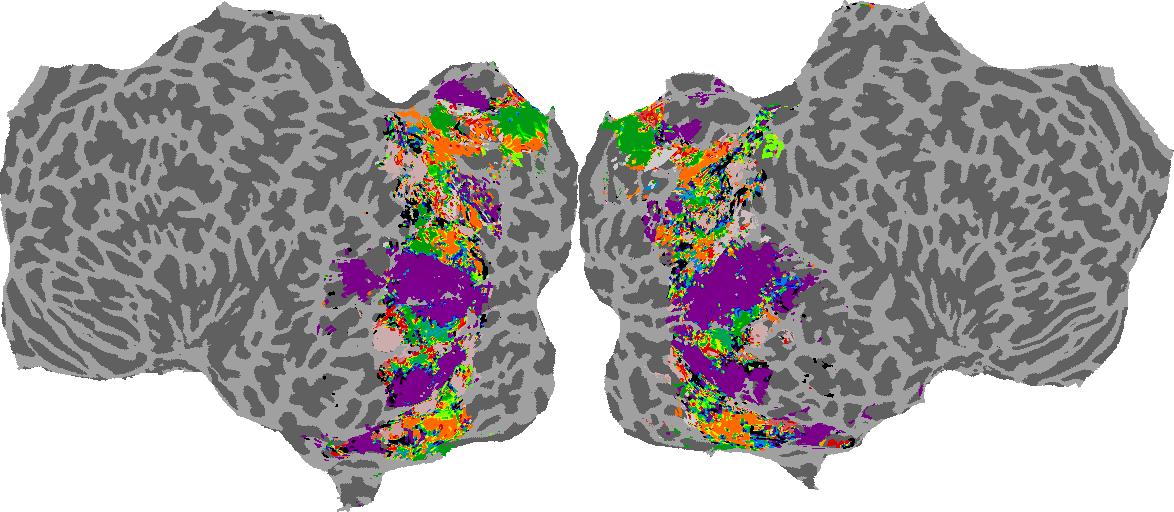
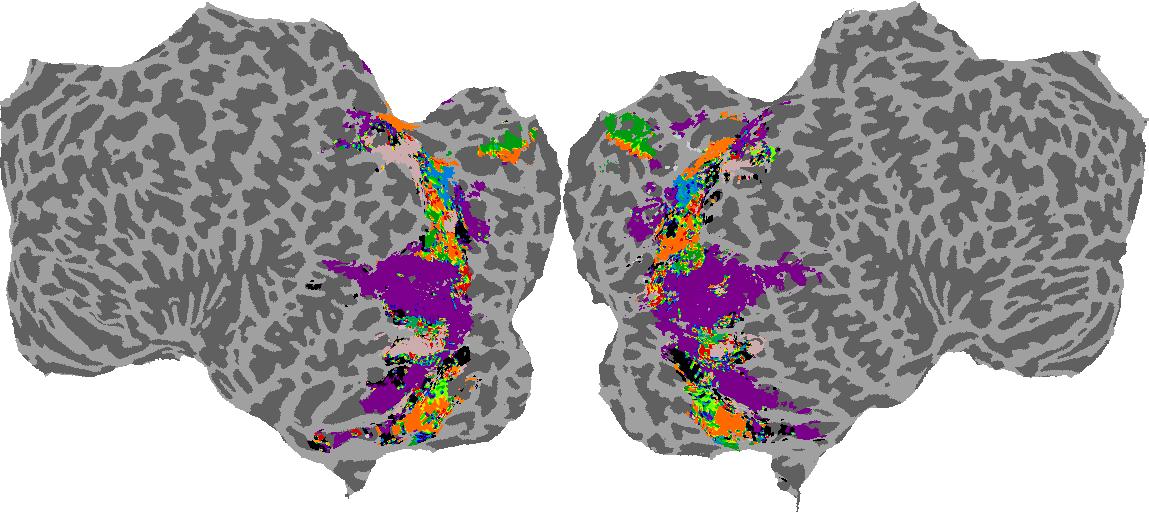
Category: N/A
High-level Visual Areas
We quantified differences in the spatial measures for high-level visual regions-of-interest (see paper for ROI definitions). Medial and Ventromedial areas show larger absolute and relative depth preferences, flatter surfaces, and darker shading, while Ventrolateral and Lateral regions prefer lower average absolute depths, curvier objects, and lighter shading.
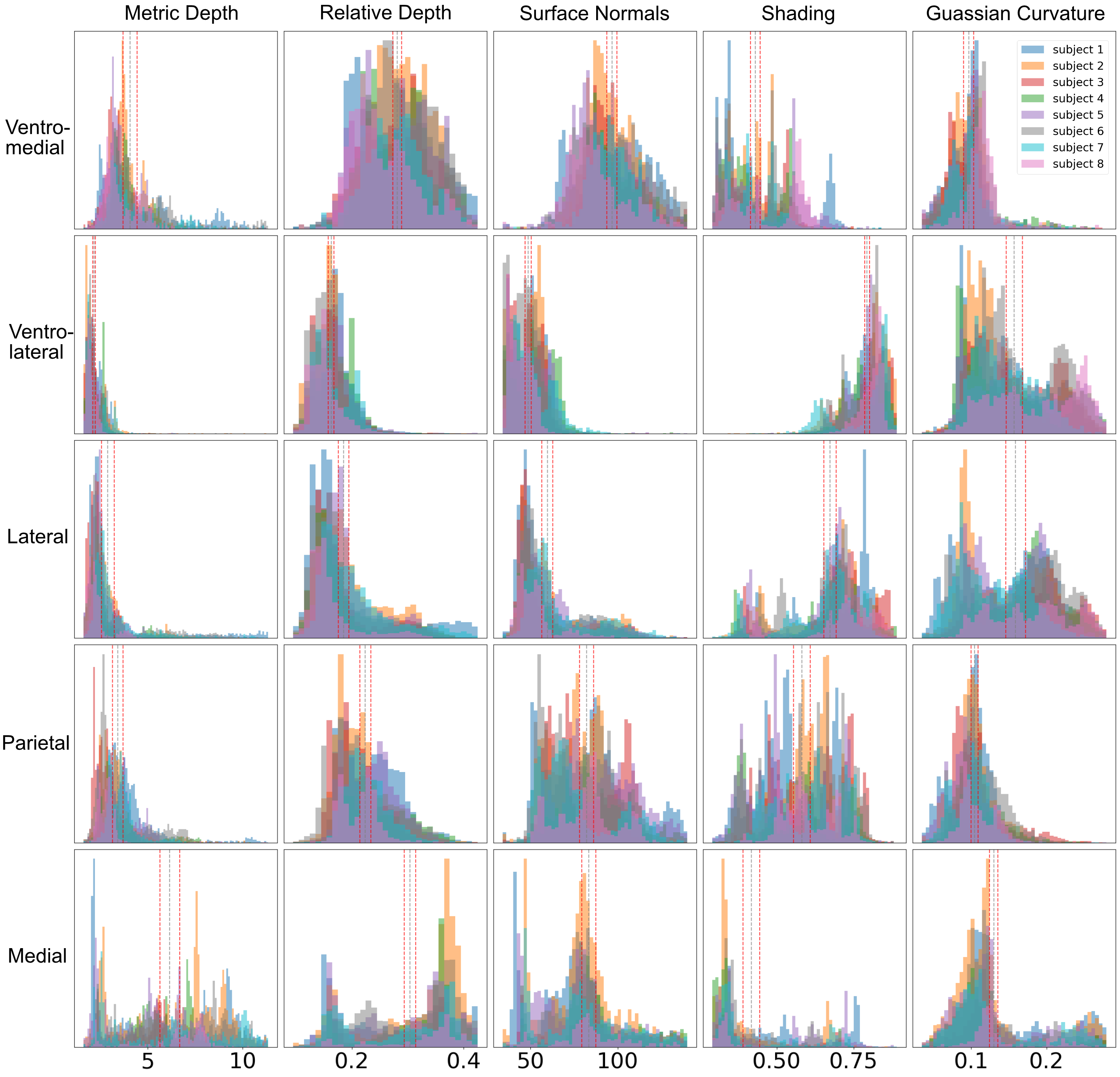
Figure. Histogram binning of voxels for each measure for the high level visual ROIs. Each color represents a different subject. Gray vertical dotted lines indicate the grand mean, and red vertical dotted lines indicate the 95% confidence intervals.
Scene Selective Areas
We quanitfied differences in the spatial measures for the “scene network”, the occipital place area (OPA), parahippocampal place area (PPA), and the retrosplenial complex (RSC). RSC appears to have a unique role in processing far spatial information and outdoor scenes, showing a preference for greater metric and relative depths, and right/left surface normals indicative of vertical structures and a possibly bodycentric representation of space. In contrast, PPA and OPA show a stronger preference for “up” surface normals, underscoring their contributions to a possibly allocentric representation of space.
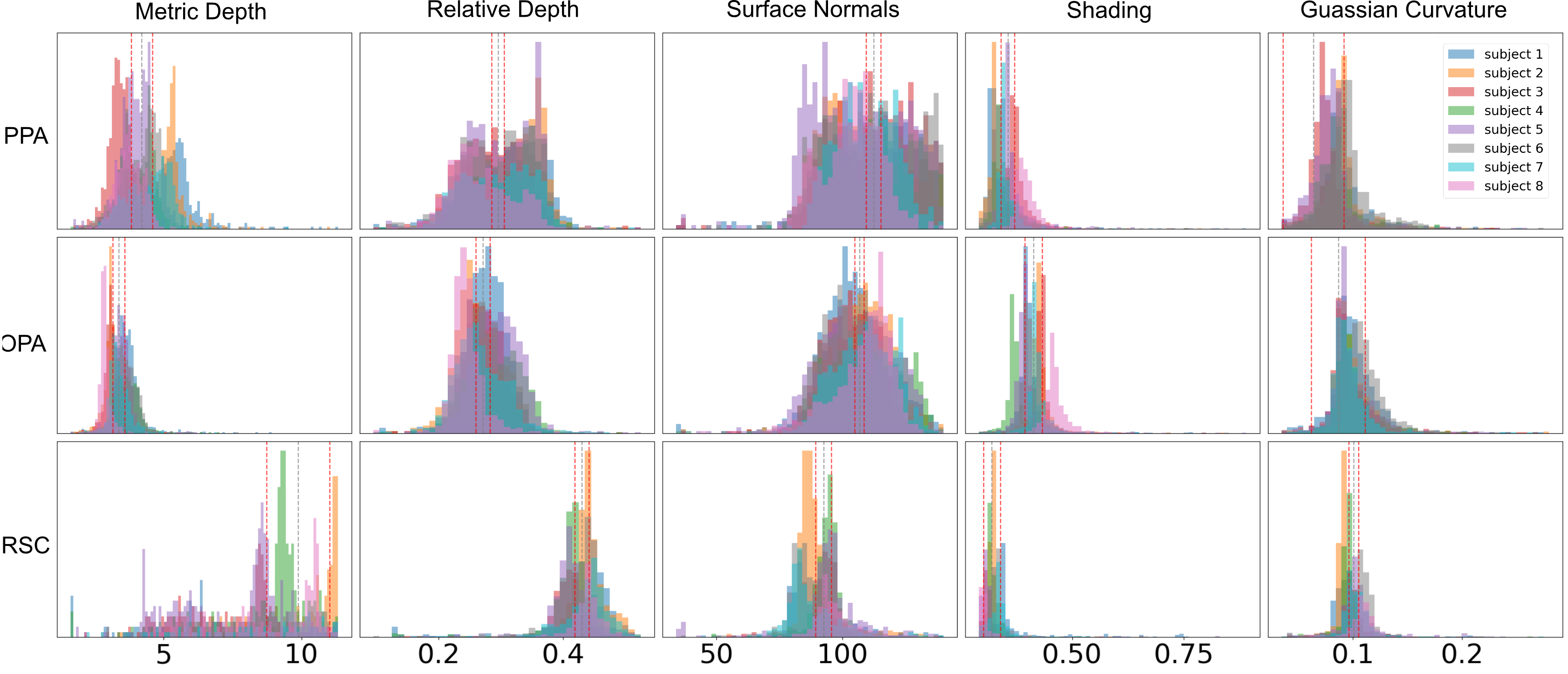
Figure. Histogram binning of voxels for each measure for the scene ROIs. Each color represents a different subject. Gray vertical dotted lines indicate the grand mean, and red vertical dotted lines indicate the 95% confidence intervals.
Object Relationships, Attributes, and Categories
We examined the most selective categories for each ROI in the GQA dataset using brain dissection. We find distinct preferences for object relationships, attributes, and categories in high-level visual ROIs, with Parietal areas favoring inanimate objects and spatial relations, Lateral areas preferring person and animate objects, and Ventral areas favoring both persons and objects, aligning with previous literature.
Scene ROIs also show distinctions. OPA shows greater selectivity for indoor scene elements, such as chairs, tables, and floors. PPA exhibits a mix of indoor and outdoor preferences, whereas RSC shows a clear preference for outdoor scene elements like trees, buildings, and the sky, once again reinforcing a dichotomy between local space interactions and navigation. Furthermore, when considering attributes, RSC again demonstrates more selectivity for “outdoor” attributes compared to PPA and OPA, which show higher selectivity for indoor elements. These findings underscore the distinct functional implications of these ROI selectivity profiles for processing visual scenes.

Figure. WordCloud for top 20 categories that an ROI selects for in the GQA dataset. In this visualization, the category size represents the magnitude of the median IOU.
See our paper for more!
Citation
@inproceedings{sarch2023braindissect,
title = "Brain Dissection: fMRI-trained Networks Reveal Spatial Selectivity in the Processing of Natural Images",
author = "Sarch, Gabriel H. and Tarr, Michael J. and Fragkiadaki, Katerina and Wehbe, Leila",
booktitle = "bioRxiv",
year = "2023"}